
This post is part of a series that already has:
- E-commerce Backend - Monolith - Overall Architecture - (Part 1)
- E-commerce Backend - Monolith - Starting with Quarkus - (Part 2)
- E-commerce Backend - Monolith - Decoupling Components with Event Bus - (Part 4)
- E-commerce Backend - Monolith - Docker Compose to run the App and Infra locally - (Part 5)
- E-commerce Backend - Monolith - Local Kubernetes with Kind - to run the App and Infra - (Part 6)
- E-commerce Backend - Monolith - Kubernetes Probes - (Part 7)
In the last post, I developed most of the functional parts of my E-commerce backend with Quarkus. In this post, I will improve its performance caching with Redis. More specifically, the endpoint that lists the products for the customer to view and add to their carts.
Quarkus Caching
What I'm caching
The endpoint mentioned above is a great candidate to be cached because it is based on a query with joins for different tables:
- Product Category
- Product Details
- Product Price
- Product Inventory
The number 4 is the only data that is expected to change frequently because it changes whenever a customer buys an item. But it's still worth it to cache because we expect the frequency of customers visiting the online store to be much higher than they buying something. Also, the inventory is used just to prevent the list from including non-available products. That means we don't need to invalidate the cache every time an item is sold, we just need to invalidate the cache when an item's stock unit is equal to 0 after being sold.
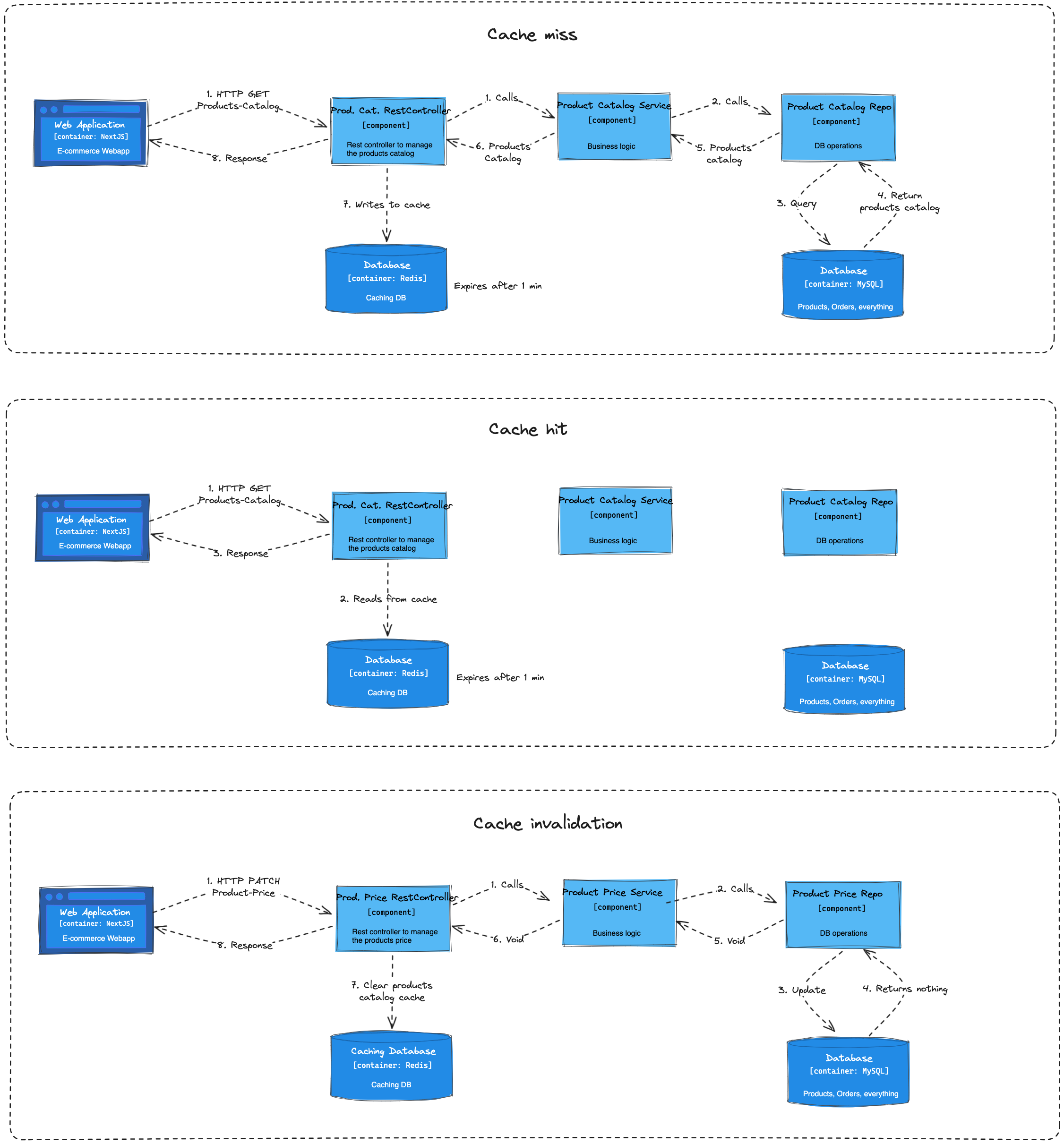
Caching with Redis
Quarkus Dev Services makes it very easy to have a Redis server running. I just need to add the redis-cache Quarkus extension and the Dev Services will take care of running a Redis container for me.
Writing/Reading to/from the Cache
The first thing we need to do is to add the quarkus-redis-cache to the project (pom.xml or build.gradle):
<dependency> <groupId>io.quarkus</groupId> <artifactId>quarkus-redis-cache</artifactId> </dependency>
By doing this, Quarkus DevServices does its magic of getting a Redis container up and running when we run our app with the DEV profile ($ quarkus dev). Amazing, right?
The next thing is to identify the method which result you want to be cached and annotate with @CacheResult. In my case, I want to cache the response of the API Endpoint that lists my product catalog in the e-commerce app:
@GET @CacheResult(cacheName = "store-products-catalog") @Operation( summary = "List all products organized by category to be listed in the store products page") @APIResponse(responseCode = "200", description = "List of all products organized by category") public Set<ProductCategoryDTO> getAll() { return appService.listProductsCatalog(); }
That @CacheResult annotation does a few tricks there:
- The most obvious, it defines that the result of that method will be cached in a cache named "store-products-catalog" in the Redis server;
- Since I haven't specified a key for the cached value, it will automatically set the key as default-cache-key
- Whenever that method is called, the Cache API will look for a cached value for that key in Redis, if it finds something, it returns it immediately, without executing the method's body.
Implementing that manually would be something like:
getAll() { cachedData = redisClient.get("store-products-catalog:default-cache-key") if (cachedData is not null) { return cachedData } data = appService.listProductsCatalog(); redisClient.put("store-products-catalog:default-cache-key", data) return data }
Regarding that generated key, for that method, a default one was generated (default-cache-key). If I had arguments to that method, a key using the values passed as argument would be part of the key. This way the cache API would be able to cache results for calls with different arguments, like in a getById method for example. The cache API also provides annotations so that we can define if a method parameter should compose the cache key or not. But I won't explore this right now.
Also, I needed to define the type of value that will stored in the store-products-catalog cache in my application.properties:
quarkus.cache.redis.store-products-catalog.value-type=java.util.Set
Now, I can check that it is working by running the following commands in my terminal:
- redis-cli -p 54450 get cache:store-products-catalog:default-cache-key : should return (nil) because there is nothing there until a first call to the endpoint;
- curl localhost:8080/store-products : to fetch data from the SQL DB first then have the cache created;
- redis-cli -p 54450 get cache:store-products-catalog:default-cache-key: this time I get the same result as the curl, because the data is there in Redis.
### Clearing the Cache
Ok, one of the challenges of caching is Invalidation.
If our data changes, we don't want to serve stale data forever.
There are two ways of discarding the cached values:
- By defining a TTL (Time-to-live). If you define a TTL of 1 minute, then your application should not use a value that is older than 1 minute;
- Invalidating the cache by its key based on an event or action.
I've defined the TTL for any key stored in the store-products-catalog to 1 minute. That's done by simply setting a Redis config in the application.properties:
quarkus.cache.redis.store-products-catalog.expire-after-write=1m
To invalidate the cache, I need to answer:
- What parts of the data I don't want to be stale, even for 1 minute?
- Where is my application that parts can be changed?
My answers are respectively: the Product Price and Inventory and their PUT endpoints. I can tolerate changes to the product name or description to wait 1 minute until the users can see the updated values. But if someone changes the product price, I don't want users to see the old price and get a surprise during the checkout. Also, I don't want to list products that just got out of stock. Cache invalidation is done by adding the @CacheInvalidateAll annotation to the method that when invoked, should invalidate the cache:
@PATCH
@CacheInvalidateAll(cacheName = "store-products-catalog")
@Path("/{id:\\d+}")
@ResponseStatus(StatusCode.ACCEPTED)
@Transactional
@Operation(summary = "Update product price")
public void update(@PathParam("id") String id, UpdateProductPriceDTO producDto) {
// TODO: handle invalid product exception
service.update(producDto, Long.parseLong(id));
}
There I'm invalidating the whole "store-products-catalog" cache. But I could use @CacheInvalidate and define the exact key to be invalidated like "store-products-catalog:default-cache-key". If I had a getById method cached, for example, the id value would be part of the key for the cached value, and I could invalidate the cache for the specific product having its price updated instead of invalidating the whole "store-products-catalog" cache.
Results
Now let's compare the results with and without caching. I used hey to run a simple load test against the API with the following command
$ hey -n 2000 -c 50 -m GET -T "application/json" http://localhost:8080/store-products
That means: Perform 2000 requests with a concurrency of 50.
Summary
| With Caching | Without Caching |
|---|---|
| Total: 2.5004 secs Slowest: 0.7532 secs Requests/sec: 799.8678 | Total: 3.9414 secs Slowest: 1.8233 secs Requests/sec: 507.4387 |
We can notice that with cache, those 2000 requests were handled in almost 60% of the time spent by the no-caching version, resulting in a higher throughput with caching. Also, the slowest request with cache took less than half the time the no-cached version slowest one.
Response time histogram
| With Caching | Without Caching |
|---|---|
| 0.001 [1] | 0.076 [1622] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.152 [262] |■■■■■■ 0.227 [59] |■ 0.302 [0] | 0.377 [8] | 0.452 [12] | 0.528 [12] | 0.603 [0] | 0.678 [1] | 0.753 [23] |■ | 0.011 [1] | 0.192 [1954] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.373 [3] | 0.555 [3] | 0.736 [3] | 0.917 [1] | 1.098 [1] | 1.280 [1] | 1.461 [1] | 1.642 [1] | 1.823 [31] |■ |
Here we can see that with the cache, the majority of requests (1622) took only 76 milliseconds. Whereas most of the no-cached requests took 192 milliseconds.
Latency percentile
| With Caching | Without Caching |
|---|---|
| 10% in 0.0144 secs 25% in 0.0220 secs 50% in 0.0360 secs 75% in 0.0564 secs 90% in 0.1090 secs 95% in 0.1662 secs 99% in 0.7032 secs | 10% in 0.0168 secs 25% in 0.0214 secs 50% in 0.0418 secs 75% in 0.0595 secs 90% in 0.0773 secs 95% in 0.0920 secs 99% in 1.7797 secs |
That's probably the most important metric in terms of request performance. Something interesting to notice is that on the 90% and 95% percentiles, the cached version seems to not be that good. I think I know the reason for that. I see this exception happening a few times in my application logs:
Unable to connect to Redis, recomputing cached value: io.vertx.core.http.ConnectionPoolTooBusyException: Connection pool reached max wait queue size of 24 at io.vertx.core.net.impl.pool.SimpleConnectionPool$Acquire$6.run(SimpleConnectionPool.java:630
The Redis database has two important configurations with the following default values for the Quarkus Redis extension:
quarkus.redis.max-pool-size=6 quarkus.redis.max-pool-waiting=24
The Redis connections are pooled. max-pool-size is the pool size, meaning it can handle 6 connections at once. All requests that come while those 6 connections are in use, go the a waiting queue. max-pool-waiting is the capacity of that queue. Since, with the help of hey, I'm performing 50 concurrent requests, both the pool and the waiting queue get out of capacity for processing more requests. I'm not sure yet why those requests that exceeded the queue capacity resulting in that exception above were not lost. I guess that it is because the Quarkus Rest doing some work to not lose them (holding for a while or performing retries? I need to find out what exactly). Anyway, I ran another test with the following configuration:
quarkus.redis.max-pool-size=10 quarkus.redis.max-pool-waiting=40
And the result is much better now: Latency distribution: 10% in 0.0118 secs 25% in 0.0125 secs 50% in 0.0136 secs 75% in 0.0149 secs 90% in 0.0169 secs 95% in 0.1027 secs 99% in 0.1542 secs
Way better, isn't it? The caching version is much faster than the no-caching one in the 95% percentile. 150ms vs 1780ms.
Considerations
It's important to note that the tests I ran were on my machine, everything was local and running on containers. In a production environment, with the application running on a different machine from the SQL database, the no-cached requests will certainly take more time to complete. Also, I just have a small data sample. ~60 products distributed in 8 categories. In production, it would be a much larger amount of data, resulting in a higher discrepancy between the performances of the cached and no cached requests.
And that's it for this post. Thanks for reading.
Repository: https://github.com/viniciusvasti/practicing-quarkus-ecommerce/tree/monolith/products-catalog-rest-api